The short version: if you collected the data yourself, it's first-party. If you bought it from a broker who doesn't know your users, it's third-party. That one distinction drives almost every real decision downstream — accuracy, privacy exposure, how you architect the backend.
What actually separates the two
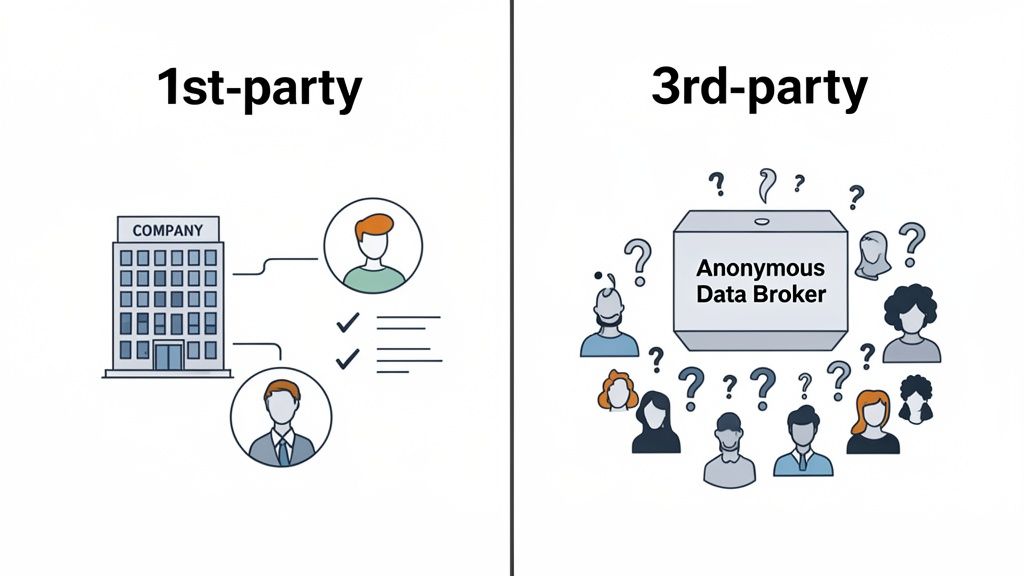
When developers argue about first-party vs third-party data, the argument is really about three things: who owns it, who consented to it, and who controls how it's used.
Every time a user signs up, clicks, or changes a setting in your app, you get a piece of first-party data. It's a direct record of what they did. It belongs to you, and the consent chain is short.
Third-party data is different. It was collected by someone else, aggregated, and sold. You get scale — behavioral data on people you've never interacted with — but accuracy is variable and the collection methods are often opaque.
Why the distinction is becoming a bigger deal
GDPR and CCPA changed the math. Direct collection with clear consent is the only setup that's unambiguously safe. Users are also paying more attention to where their data goes, which means implicit or bundled consent is increasingly a liability, not a shortcut.
If you build on first-party data, your personalization is based on what users actually did. If you build on third-party data, it's based on someone else's guess about what they might do.
The broader shift — browsers killing third-party cookies, privacy laws tightening, AI models needing cleaner training data — is pushing most product teams to rethink how they collect and store user information. Not because it's trendy, but because the old approach is getting more expensive and more risky.
| Feature | First-Party Data | Third-Party Data |
|---|---|---|
| Source | Collected directly from your own users and platforms | Aggregated from multiple external sources by a data broker |
| Accuracy | High; based on direct user interactions and inputs | Variable to low; often inferred or modeled, not deterministic |
| Privacy | High; clear consent mechanisms and direct user relationship | Low; consent is often indirect or bundled, raising compliance risks |
| Cost | Low acquisition cost, but requires investment in collection tools | High acquisition cost, often purchased on a subscription basis |
Comparing the two in practice
The decision between first-party and third-party data isn't purely technical. It shows up in product performance, user trust, and long-term risk. Here's where the real tradeoffs sit.

Accuracy
First-party data is deterministic. A user clicked something, submitted a form, made a purchase — you recorded it. There's no inference.
Third-party data is probabilistic. It's usually modeled from multiple sources to guess at demographics or interests. That's fine for broad audience analysis. It's a bad fit for anything user-facing where "close enough" will cause problems.
Privacy and consent
First-party data lets you own the consent flow end to end. You know what you asked for, you know what the user said yes to, and you can show the audit trail when a regulator asks.
Third-party data comes with consent chains you can't fully verify. If the broker's collection method was shaky, that's now your problem, both legally and reputationally.
Third-party data trades control for scale. For anything mission-critical — authentication, billing, personalization — that trade usually doesn't pencil out.
Integration cost
First-party data means you pay upfront in infrastructure: event tracking, storage, analytics. Once built, it's yours and it's cheap to operate.
Third-party data usually arrives via API, which means an external dependency that can go down or change pricing. The API economy is big but fragile — 71% of businesses use third-party APIs, and 60% say they spend too much time troubleshooting them. You can read more on that here. You pay twice: once in subscription fees, and again in engineering time keeping the integration alive.
First-party vs third-party data: side-by-side
| Dimension | First-Party Data and APIs | Third-Party Data and APIs |
|---|---|---|
| Accuracy | Deterministic: Based on direct, verifiable user actions. High reliability for core product functions. | Probabilistic: Often inferred or modeled. Risk of inaccuracy and outdated information. |
| Privacy & Consent | High Control: You manage the entire consent lifecycle directly with the user, ensuring compliance. | Low Control: Consent is indirect and often opaque, creating significant compliance risks. |
| Integration | Internal Dependency: Requires upfront build-out but offers long-term stability and control. | External Dependency: Faster to implement initially but introduces vendor lock-in and maintenance overhead. |
| Cost | Operational Cost: Investment in infrastructure and engineering to collect and manage data. | Subscription Cost: Direct fees for data access, plus hidden costs of integration and maintenance. |
The real answer is usually "it depends." Personalizing a dashboard with a user's own activity is first-party, always. Enriching a user profile with public company information is a fine use case for a specialized third-party API. The mistake is treating them as interchangeable.
Why the shift to first-party is picking up speed
This isn't a slow trend — it's a market correction. For the better part of two decades, a lot of the digital ad stack was propped up by third-party cookies that tracked users across sites. That infrastructure is being dismantled on a timeline measured in months.
Major browsers are phasing out third-party cookies. Safari did it years ago. Firefox too. Chrome is the last big holdout, and their rollout has been messy, but the direction is clear. Any product that depended on cross-site behavioral data is being forced to change.
The privacy demand isn't slowing down
Users have gotten more sophisticated about this stuff. Not all of them, but enough to move the market. GDPR and CCPA codified what a lot of users had started to expect anyway — explicit, specific, revocable consent.
What used to be a compliance checkbox is now a product requirement. If you can't show users what you collect and why, you lose them.
The competitive advantage isn't how much data you have. It's how much of it you got honestly and how useful it actually is.
AI is pushing this harder than anything else
LLMs need data. Good LLMs need good data. And the kind of sludgy, over-aggregated third-party datasets that worked fine for ad targeting are a disaster for training personalization models.
First-party data is the format of choice for AI features because it's clean, consented, and specific. The deprecation of third-party cookies in Chrome (which has over 50% global browser share) is expected to wipe out most of the remaining third-party cookie footprint. You can read more on the 2025 first-party data outlook here.
If you're building AI into your product now, you need a first-party data pipeline. That's not a nice-to-have. And once you have it, you'll probably want to figure out how to identify anonymous website visitors too, so the anonymous side of your funnel doesn't go dark.
First-party data is the core of any modern product strategy, but on its own it's thin. It tells you what a user does in your app. It says very little about who they are in the rest of the world.
That's where a hybrid approach — first-party plus a specialized third-party API — becomes worth thinking about.
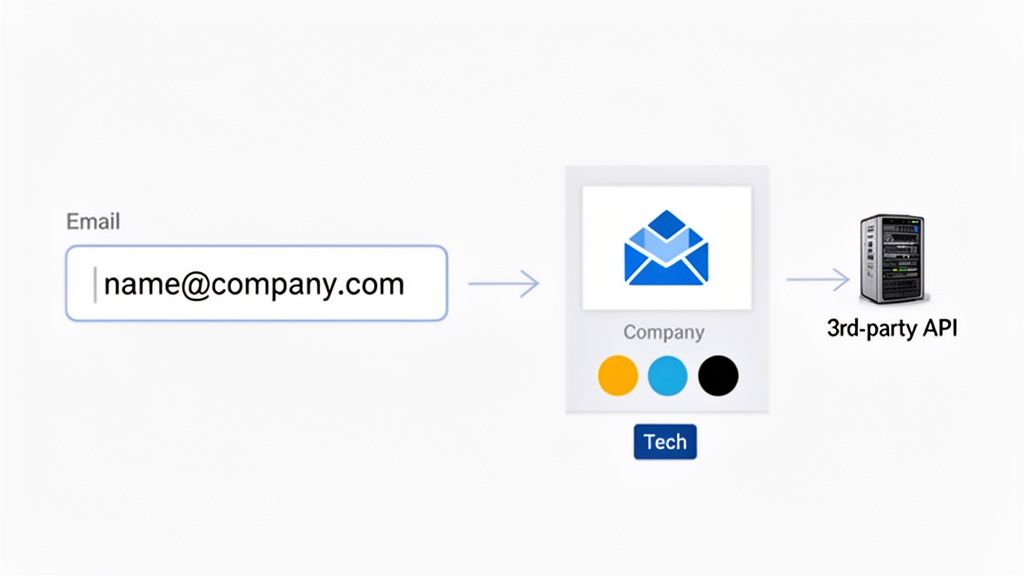
The pattern is simple: take a first-party signal you already have (the user's email), and use it to pull public, non-sensitive information about their company. The user's privacy stays intact because you're not pulling their personal data — you're pulling facts about where they work.
This isn't niche. 82% of organizations now say they run an API-first approach. Of the 25% that are fully API-first, 43% generate over a quarter of their revenue from APIs.
Turning a domain into a brand in one call
This is what services like Context.dev do. When a user signs up with a work email, one API call against the domain returns a full brand kit:
- Logos — for use in dashboards, welcome emails, anywhere the user benefits from seeing their own company reflected back
- Brand colors — for theming the UI on first login
- Company description — for CRM enrichment
- Industry data — for segmentation and onboarding paths
You already had the email. Now you have everything you'd have asked the user to type in a signup form, without asking. If you're looking for adjacent patterns, this brand monitoring guide covers some useful public-data workflows.
This doesn't replace first-party data. It sits on top of it. You're using a first-party signal as the key to a third-party lookup that's constrained to public information.
Where this actually lands in a product
A SaaS team using a company data API can skip the empty-dashboard problem entirely. A new user signs in, the dashboard pulls their company's logo and colors, and the product instantly feels like it fits into their workflow.
Sales and marketing teams get the same benefit on the CRM side. Records auto-populate with company logos, descriptions, industry data. A rep opens an account and has context without having to go look it up.
The point of the hybrid approach is that it fills in what first-party data can't tell you, without touching anything sensitive. You don't know the user's personal behavior on other sites (good), but you do know what their company is (useful).
The theory of first-party vs third-party is fine, but the actual win is when you stop picking sides. A hybrid strategy uses one piece of first-party data — something the user gave you directly — as a lookup key for public enrichment. You get deep personalization without going anywhere near a data broker.
For SaaS, this is the pattern that shows up again and again. Here are three ways to put it into practice.
Onboarding that fills itself in
Email is the ideal first-party key. Domain from email → company data → personalized UI.
- Collect the email. User signs up with
jane@acme.com. - Call the API. Backend sends
acme.comto a brand API. - Get the data back. A JSON object with the logo, colors, name, and description.
- Render it. The new dashboard shows Acme's logo and uses Acme's colors.
One API call, a noticeably better first-run experience. The user doesn't have to do anything extra.
This turns a signup form into a personalization trigger. Low friction, immediate payoff.
Cleaning up transaction data
Fintech products have a specific version of this problem: transaction descriptions are cryptic. "STRIPE-ABC Inc." on a statement is confusing and slightly alarming.
A brand API can translate that into something recognizable. Send the company name in, get back the clean name ("ABC Incorporated") and the logo. One step, and support tickets about "what is this charge" drop significantly. If you're building anything with a financial component, this is worth looking at — more on it in our guide to B2B data enrichment.
On-brand AI output
LLMs don't know what your user's brand looks like unless you tell them. A hybrid strategy gives you a clean way to feed that information into the prompt.
- The flow: User asks the AI for a marketing email. Your system first pulls the user's company brand kit from a brand API.
- The prompt: That data goes into the LLM prompt as context. The model generates copy that uses the right colors, tone, and voice.
The output comes back on-brand without the user having to manually edit it. Products like SupportGPT use this kind of contextual data injection to make AI output actually useful in production, not just demo-ready.
The pattern generalizes: AI + first-party signal + third-party enrichment = output that fits the user's actual context.
Picking a data strategy
The first-party vs third-party debate is really a scoping question. You're not picking a winner for your whole stack — you're deciding which parts of your stack need which kind of data.
For anything involving user authentication, personal information, or sensitive in-app activity, the answer is first-party data. Full stop. This isn't a place to compromise.
The hybrid middle ground
A strict first-party-only rule leaves useful context on the table. The hybrid model solves that: use a first-party signal as the key to unlock public, non-sensitive third-party data.
This flow shows how a hybrid strategy turns one signal into a personalized experience.
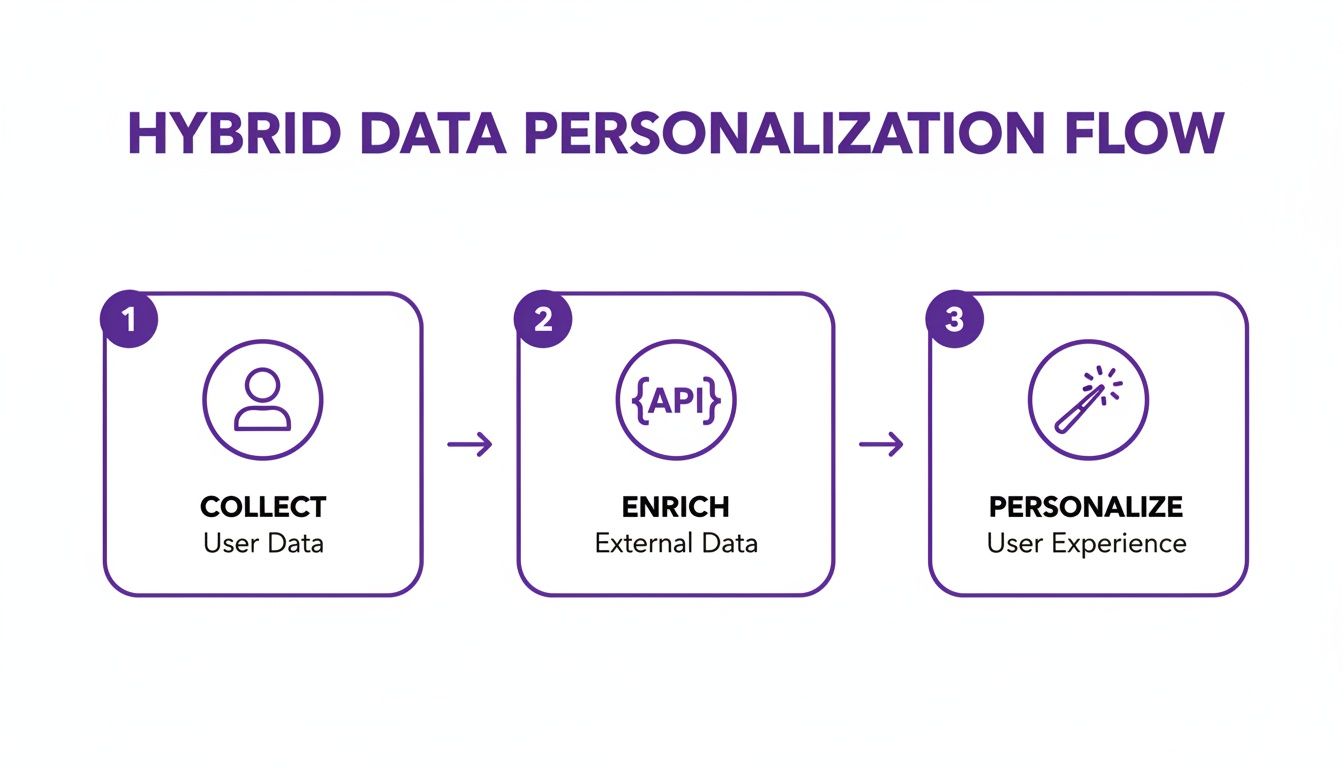
Collect one first-party signal, enrich via API, render a personalized result. That's the whole loop.
The upside: you keep the sensitive core locked down, and you get the contextual richness that first-party data alone can't give you. It also solves the cold-start problem for new users — they see a personalized product on the first login, not after a week of usage.
The best data strategies aren't absolutist. They protect core data with a first-party wall and augment it with trusted, specialized third-party sources where the tradeoff makes sense.
A decision framework
If you're trying to decide where to draw the line, this is a good starting point:
- Security and core user data: 100% first-party. Passwords, personal details, user-generated content. No exceptions.
- Onboarding and personalization: Hybrid. Use first-party signals to fetch public brand/company data.
- AI and content generation: Hybrid. Inject structured brand data into prompts so output stays on-brand.
Stick to that and you get a system that's compliant, secure, and still personalized enough to drive engagement. The goal isn't to pick a side — it's to know which side each piece of your product is on.
Building a hybrid data flow? With Context.dev, you can enrich user profiles with logos, colors, and complete brand kits from a single API call. Start building for free.